C3NET: Demoireing Network Attentive in Channel, Color and Concatenation. (CVPRW 2020) NTIRE 2020 6th
- Authors: Sangmin Kim, Hyungjoon Nam, Jisu Kim, Jechang Jeong.
-본 논문에서는 moire를 제거하기 위해 C3Net(Channel, Color, Concatenation)을 제안했다. 본 논문에서는 최근 우수한 성능을 보이는 attention mechanism(e.g. channel attention, spatial attention)에서 channel attention을 사용한다. 이는 moire를 제거하는 것은 color-related 문제이며, RGB채널 안의 정보가 모아레 제거에 도움이 된다고 가정한다.
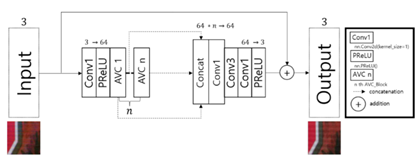
-제안하는 C3Net은 AVC(Attention Via Concatenation) Block으로 구성된다. trunk branch는 input image의 information을 전달하고 mask branch의 U-net구조를 통해 multi-scaled information을 산출한다.
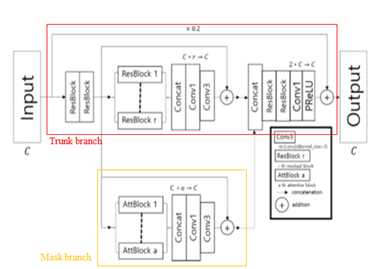
-ACV block은 trunk branch와 mask branch로 구성된다. trunk branch는 residual block과 channel attention module을 가진 residual block을 연결하며 parallel하게 다양한 feature들을 feature map으로 추출하는 역할을 수행한다.
- mask branch는 ATT Block을 parallel하게 연결하여 마찬가지로 multi-scaled information을 추출하는 역할을 수행한다. ATT Block은 Resblock으로 이루어진 U-net의 형태이다.
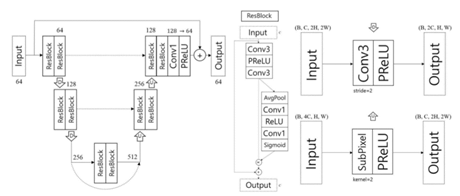
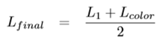
-본 논문에서 NTIRE2020 demorieing dataset을 분석한 결과 moire 제거에 color-related를 중요시 생각하며 L1 color loss function을 적용한다. Color loss function은 image의 U, V channel을 측정한다. Color loss와 L1 loss를 average하여 최종 loss function을 만들어낸다.
-channel attention
: 최근 NLP에서 우수한 성능을 보인 attention mechanism을 image processing에 적용하면 attentive neural network는 image의 channel들 사이에서 계산된 weight를 이용한다.
-spatial attention(pixel attention)
: 이미지의 pixel 위치에 attention을 진행하며, 원하는 결과를 위해 image의 pixel에 더 많은 weight를 부여한다. 추출된 feature map은 sigmoid function을 통해 0~1사이의 범위로 mapping되고mapping 되고, 0~1로 mapping된 weight를 다시 input과 곱하며 전체 네트워크는 더 나은 결과를 만들어낸다.




댓글