Attention for extract essential feature map
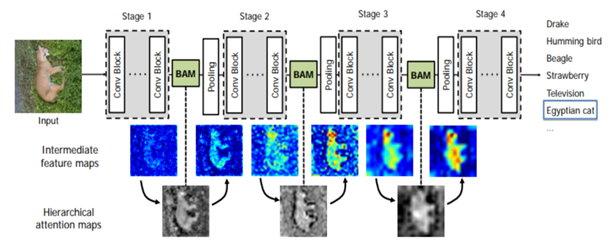
-Attention Module Effectiveness: 아래 Figure 1을 통해 attention의 효과를 확인할 수 있다. BAM(Bottleneck Attention Module)을 통해 추출된 attention map이 intermediate feature map에서 essential한 feature를 강조하고, 불필요한 부분은 억제하는 것을 확인할 수 있다.
Channel attention, Spatial attention, Channel & Spatial Attention
-Channel Attention: channel attention은 feature map의 channel간의 관계를 이용하여 특정 channel을 강조(attention)한다. 구조는 아래 Figure 1과 같다. 이를 식으로 표현하면 eq.1과 같다.
1. Input feature map은 global average pooling(GAP)를 통해 channel size의 벡터가 되며 각 값은 해당하는 channel을 대표하게 된다.
2. 이후 벡터는 첫 번째 Fully Connected layer(fc1)를 통해 유의미한 정보를 갖는 벡터로 압축되며, activation function σ1 (Leaky ReLU)를 통해 비선형성을 가지게 된다.
3. 그 다음 두 번째 Fully Connected layer(fc2)와 activation function σ2 (Sigmoid)를 통해 압축된 벡터는 0-1 사이의 값을 갖는 channel size의 강조(attention)된 벡터로 만들어진다.
4. Attention된 벡터는 input feature map을 scaling하며 최종적으로 channel이 강조된 feature map이 만들어진다.


-Spatial Attention(Pixel Attention): 단일 층을 이용한 Spatial Attention은 input feature map에 1x1 convolution layer를 적용하여 pixel별로 channel의 information을 취합하고, 1개 channel에 attention된 feature map을 만든다. 이후 강조된 feature map으로 input feature map을 scaling 하여 attention된 feature map이 만들어진다. 이를 수식으로 표현하면 eq.2과 같다.


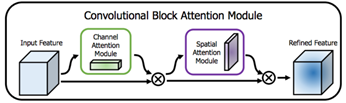
-Channel & Spatial Attention: CBAM block에서 제안된 channel attention과 spatial attention을 모두 사용한다. Channel attention을 먼저 수행하는 것이 성능이 더 우수했다.
Reference:
1. https://arxiv.org/pdf/1807.06521.pdf
2. Attention 모델을 이용한 단일 영상 초고해상도 복원 기술-문환복, 윤상민
'딥러닝(Machine Deep learning)' 카테고리의 다른 글
| Multi-Task Learning-Optimization Strategy [1] (0) | 2022.07.05 |
|---|---|
| Ubuntu 20.04, RTX 3070에서 cuda toolkit 및 드라이버 설치하기 (0) | 2022.06.23 |
| What is different between concat & element sum (0) | 2020.02.12 |
| 딥러닝 개발을 위한 윈도우 텐서플로우 설치방법 (0) | 2019.03.07 |



댓글