Squeeze-and-Excitation Network (CVPR 2018)
Authors: Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu
- 본 논문에서는 Squeeze와 Excitation 2개의 과정을 통해서 이전 CNN이 local receptive field만 가지고 학습을 하기 때문에 채널단위의 전체적인 정보 (global feature)를 반영하지 못한다는 한계점을 극복한다. Squeeze operation의 global average pooling을 사용하여 1x1 채널단위 feature map으로 압축 후(global feature 반영), Excitation operation의 recalibration으로 re-weight하여 채널 간의 중요도 학습을 이루어낸다.

- Squeeze-global information embedding. Global distribution(information) embedding을 수행한다. 각 채널들의 중요한 정보만 추출해서 가져간다. 본 논문에서 global average pooling이 제일 성능이 좋아서 이를 통해 압축한다. Channel Descriptor를 만들어 global spatial information을 표현한다. 이 descriptor는 channel-wise feature response의 global distribution(information)을 임베딩하여, 네트워크의 모든 layer에서 global receptive field로 얻을 수 있는 information을 사용할 수 있게 한다.

- Excitation-adaptive recalibration. Adaptive recalibration을 수행하며 re-weight한다. 채널간의 의존성을 계산하며 fully connected layer와 비선형함수로 이를 조절한다.

- σ는 시그모이드이고, δ는 ReLU이다. 먼저 squeeze를 통해 얻은 결과를 W1가중치들과 fully-connected하게 곱한다. 그 output 을 RELU로 활성화하고 W2 가중치들과 fully-connect하게 곱하고, 여기서 다시 한번 그 output을 시그모이드함수로 활성화하여 0-1사이의 값을 가지게 한다. 이를 통해 각 채널의 상대적 중요도를 0-1사이의 값으로 파악할 수 있게 된다.
- 또한 2개의 Fully Connected Layer는 bottle-neck의 구조를 가진다. 이는 hidden layer의 뉴런을 input layer보다 작게 하고 다시 output layer에서는 뉴런의 수를 input과 동일하게 하는 방식이다. 이렇게 하면 하이퍼 파라미터의 수가 많아지는 것을 방지한다. Hidden layer의 뉴런의 수는 reduction ratio, r을 통해서 결정되며 이는 실험 결과를 통해 본 논문에서는 16으로 결정한다. r이 클수록 hidden layer의 뉴런 수는 적어지고, 복잡도도 더 낮아지게 된다. 따라서 각 층의 뉴런의 개수는 채널의 개수인 C에서 시작해서 C/r로 감소하고 다시 C로 증가한다. 이렇게 만들어진 C개의 sc를 uc에 각각 곱해줘서 U를 재보정한다.
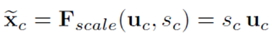
- Input X는 feature map U로 변환되고 squeeze의 global average pooling을 통해 feature map을 크기가 채널단위(1x1)로 작아진다. 이렇게 축소된 feature map을 하이퍼 파라미터(실험을 통해 얻은 축소비율)로 채널단위로 축소하고, 다시 확장하여 채널수가 squeeze 전의 feature map과 곱함으로 중요한 feature를 강조할 있다.
- 정리하자면, Squeeze 연산을 통해 압축된 정보들의 채널단위 연관성을 파악한다. 그리고 두 번의 fully-connected layer와 비선형 활성화 함수(sigmoid,RELU)를 통해 중요한 특징 부분을 attention할수 있다. 축소 비율은(하이퍼 파라미터)는 fully-connected layer의 연산량을 줄이기 위함이고, 여러 실험을 통해 이 비율을 16이라고 말한다. 마지막으로 attention된 feature map을 squeeze이전의 feature map과 곱하여 중요한 feature를 강조하는 효과를 만들 수 있다.
- 마지막으로 이 SE block은 기존의 CNN의 모델에 유용하게 사용될 수 있다.





댓글